
Introduction to spare parts purchasing in industry 4.0
One of the biggest challenges in asset management industries is managing the purchase of spare parts. Estimating the useful life of spare parts in order to maintain an adequate replacement inventory, as well as having a clear understanding of the future demand for these spare parts, helps to improve predictive maintenance metrics. In this post, you’ll learn how machine learning models are revolutionizing spare parts purchasing in Industry 4.0.
Currently, knowing how long a piece of machinery will last or when it will fail is one of the big operational problems that needs to be known with greater precision to optimize decision-making and improve companies’ budget allocation.
This problem is specific to Industry 4.0, a new way of producing through solutions focused on interconnectivity, automation and real-time data.
And this is where an important factor comes into play: the criticality of running out of spare parts for the periodic maintenance of each asset, taking into account the risk level of each industry or sector of activity. Not replacing this spare part is not an option, as many people, human lives and economic activities depend on it.
Various types of industries that make intensive use of equipment, such as aviation, telecommunications, nuclear power plants, and many others, often require large quantities of spare parts to ensure high system availability, which in turn generates excessive inventory costs.
Is it possible to estimate more accurately when the useful life of each spare part will end and to manage maintenance more efficiently based on this data?
To answer this question, it is necessary to show what the main maintenance models of today’s industries are:
- Run-to-failure: This is reactive maintenance because assets are sent for repair only after they fail. It is not a viable long-term solution for repairable assets. When a critical failure occurs, it can cause unnecessary delays in production that can cost more in lost production time than it would have cost to implement a more proactive maintenance strategy in the first place.
- Preventive: This is maintenance that consists of tasks that are periodically scheduled (planned) to avoid future anomalies and unforeseen events, as it is about fixing assets before they fail. Like annual maintenance (or mileage-based maintenance for consumer vehicles), preventive maintenance is usually based on time or usage, following the equipment manufacturer’s recommended schedule and checking equipment during scheduled maintenance visits. It generally has limitations, as it can lead to unnecessary replacement of parts that are still in good condition, and is often aimed at preserving low or medium priority assets that are very expensive to repair.
- Predictive: This is data-based and consists of building a model to predict the useful life of spare parts as effectively as possible and also to estimate failures. It is typically designed to predict failure trends through condition monitoring and machine learning algorithms that use a model to adjust physical resource allocation. It also enables teams to identify maintenance issues in real time, rather than waiting for a scheduled maintenance visit or an unexpected machine failure. Condition monitoring technology immediately alerts staff to potential problems so they can be addressed before they escalate.
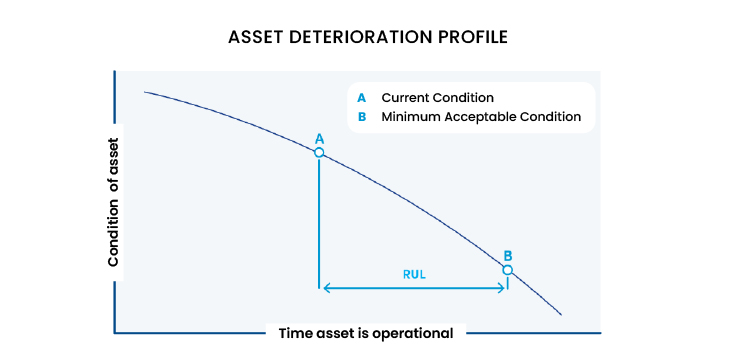
It should be noted that in practice there is usually a mix of these different types of maintenance, and within spare parts purchasing there is this type of metric called RUL (Remaining Useful Life) records, which indicate the remaining useful life of a part.
In the following graph we see that it has this determined curve: as the time passes, the condition of the asset decreases and it becomes more noisy. If we stop at point A, the RUL is the time that we have left until we reach point B, which is the moment when the part will be in a condition that cannot be accepted.
Challenges in Estimating Service Life of Spare Parts
Typically, an operator keeps a tracking spreadsheet for each of the thousands of spare parts. In this spreadsheet, he enters the part code with an inventory number, the average RUL time, the lead time -which is the amount of time that the part will take from the date of purchase- and the replacement cost.
It is important to note that the lead time can never be greater than the RUL, otherwise we would be left with unreplaced parts and that would be a risk to our assets and operations.
In this way, we have a history with time series of records of each of the parts and we can make predictions of this RUL with a certain margin of error.
To make these estimates, you can use not only historical data, but also the average time indicated in the manufacturer’s manual or Condition Base Monitoring (CBM), which includes various methods such as vibration sensors, nondestructive testing and surveillance video.
The problem is that companies generally do not have an unlimited budget, and they need to optimize their budget allocation based on being able to estimate the future demand for these parts.
Obviously there are parts that are very expensive, there are lead times that are very long, and in general we cannot stock everything.
Also, the problem is that the inventory we want to maintain cannot cover spare parts for everything, either because we have specific budget constraints, or because there are spare parts that are very expensive and we only replace them when they are about to break.
And here is a fundamental aspect of where machine learning comes in to provide actionable knowledge for decision making.
There is a clear difference between estimating the useful life of a part and being able to predict when it will fail, because the fact that a part is not acceptable according to maintenance parameters does not mean that it is broken.
And the cost of repairing a failure at the end of its useful life is usually higher (in the case of a human causing a car accident, it is more expensive because the civil and legal consequences of failing to maintain it are greater).
So one thing is to be able to determine the useful life (with an ML model) and another thing is to predict a failure or anomaly based on the use of the asset, which is what predictive maintenance tries to do.
Optimization Models and the Budget Allocation Problem
In summary, a machine learning optimization model considers the following parameters as reliable and operational:
- RUL: remaining useful life of the part of our asset.
- Lead time: delay time to obtain this spare part.
- Cost: budget to invest for this part according to the supplier.
- Prediction: it is a prediction or forecasting model that calculates an average of the time we have for each part and that always has a margin of error.
- Confidence interval: it is this average +- margin of error, considering that they are not exact values, each of the variables of the model always has a confidence interval that provides the values most compatible with our real data.
If we are in a complex industry, we will have about 10 or 20 thousand technical records, and even then we cannot have inventory of everything, because of a question of prices. Otherwise, the cost of our inventory is very high.
This is the classic «Budget allocation» problem, which has to do with optimizing the budget for spare parts. A useful analogy for understanding and solving this problem is the «backpack problem», an algorithmic problem involving heuristics and combinatorial optimization.
As you can see in the drawing below, the backpack has a maximum capacity, we have to fill it with things, but we cannot exceed the maximum weight of the backpack, and we have to try to put in the things that are most valuable. Then we have the weight of each thing and how much it is worth, and we have to come up with an optimal way to allocate scarce resources.
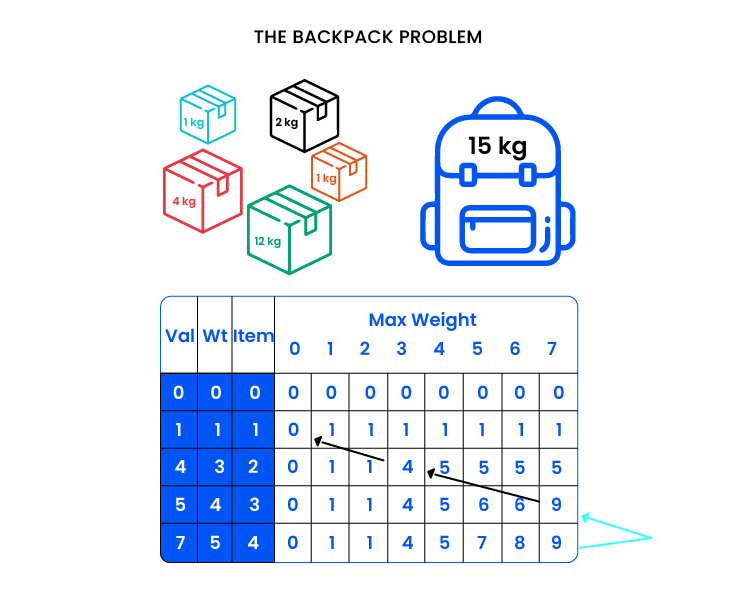
No doubt this problem is well studied. And machine learning for these kinds of situations has developed a lot; there is a whole scientific library of references on how to solve it.
It is important to know that you can end up with «constraints», which are rules that are applied to the data in the databases. For example, if we buy this spare part X, we have to buy these two Y, Z, and for this spare part K there is a minimum quantity (n) that we can order from the supplier.
We may even have restrictions related to the supplier, lead time, or import of parts. In general, there are always rules for purchasing, we cannot buy anywhere and in any quantity.
At the moment there are very well organized companies that have a lot of purchases and want to organize them efficiently.
So it is important that the people who do the inventory see it this way, with the same «backpack problem», how the search for the best solution can generate an excessive level of computation, more so when we are talking about estimates, and that it is an NP problem because there is no fast algorithm that can solve it a priori.
In this way, we combine a decision model for the purchase of spare parts with a forecasting model (estimation and analysis of future demand through algorithms) of the parts of our assets.
How does that work in practice?
What can happen is that we estimate that a part has lost its useful life or the lead time is going to be so long on average, we make decisions based on this information, but then things happen, maybe the part that we thought had the most useful life left broke and in that period we put it aside and since it broke we had to do corrective maintenance.
So the recommended periodic cycle (as shown in the chart below) is to update the predictive model each period and re-estimate the RUL to then optimize the assembly of purchase orders, execute the purchase orders and plan the maintenance of the spare parts. This is a continuous cycle that is not without its problems.
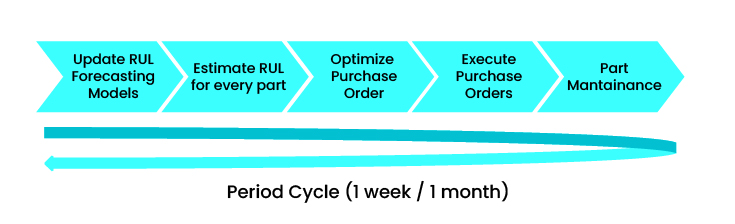
In this sense, this cycle can last a week or a month, but it starts again for each part or group of parts to be renewed. And it is important that this historical data is always recorded, updated and re-predicted what the RUL is for each of the parts to know what we have to buy next week.
This has many benefits. On the one hand, it improves our inventory management, but on the other hand, it helps us estimate the RUL and improve our predictive maintenance metrics.
Because if we continue to do preventive and predictive maintenance correctly, we improve our forecasting model and we never run out of inventory. This is usually not a problem for a very large company with a large budget, but it is for a million small and medium sized companies in different industries.
7Puentes: Building an effective ML Model to manage the purchase of spare parts
At 7Puentes, we have more than 15 years of experience in developing solutions to this type of problem, in the development of machine learning models applied to Industry 4.0. We offer your company the opportunity to accurately predict the demand for your spare parts, optimizing inventory and budget with our AI-based demand forecasting solution. Leverage the power of AI to make data-driven decisions that keep your business ahead of the curve in today’s dynamic marketplace.
Some of the benefits you will experience include:
- Revenue maximization.
- Reduce costs.
- Improved inventory management.
- Increased customer satisfaction.
Our key features for accurate forecasting are:
- Real-time data analysis.
- Advanced predictive analytics.
- Customizable predictive models.
- Easy-to-use interface.
- Robust reporting and insights tailored to each client.
Are you ready to take the leap in quality and improve your decision making with accurate parts purchase forecasting for your business? Contact our business experts today.
