
Vector databases are on the rise. They are designed to store, manage, and index massive amounts of vector data, making them ideal for large language models (LLMs) and generative artificial intelligence (GenAI). At the same time, their use is being enhanced and personalized with RAG techniques. However, ingesting the right data, providing the appropriate and multimodal context with the right embeddings, and understanding which technology we need for each use case become the main challenges to be solved. We invite you to explore the potential of machine learning with vector databases!
As Artificial Intelligence (AI) and Machine Learning (ML) applications become more complex, new problems arise due to technological innovation. In this sense, vector databases are growing rapidly to add value to GenAI use cases and applications. This is because the nature of data has undergone a profound revolution. No longer limited to structured information that can be easily stored in traditional databases, unstructured data is growing at 30 to 60 percent annually and includes social media posts, images, videos, audio clips, and more.
According to Gartner, by 2026, more than 30 percent of enterprises will have adopted vector databases to support their business models with relevant business data. However, there are clearly more proofs of concept than real, standardized solutions in the enterprise.
Unlike traditional relational databases with rows and columns, data points in a vector database are represented by vectors with a fixed number of dimensions that are grouped based on similarity. This design allows for low-latency queries, making it ideal for AI-driven applications.
To understand what these vectors are, in the database world, vectors are matrices of numbers that can represent complex objects such as words, images, videos, and audio generated by an ML model. For this reason, high-dimensional vector data is essential for machine learning, natural language processing (NLP), and other AI tasks.
An example of the sophistication of these document database technologies is the use of so-called «inverted indexes,» tools that allow us to type words or search terms into search engines, locate them in certain indexes, and tell us which documents they appear in. Or specific questions (queries) that return answers.
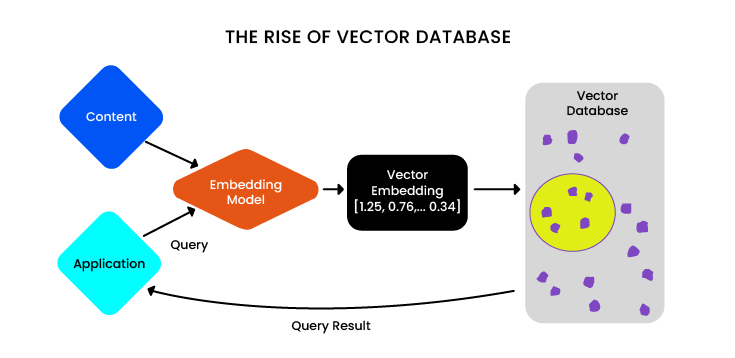
LLMs and the problem of embedding
With the development of facial recognition technologies or fingerprint vectors, it is not a raw image that is stored, but the encoded content of the image. This is a clear example of data encoding that we call «embedding», something that has evolved to the point where we have embeddings that are independent of applications. They are not going to be 100% tailored to the application, but they are more generic. Because with the LLMs and this new encoding, such a massive process has been achieved that many types of content have been vectorized (for example, you are going to take a photo of a tree and the model recognizes that it will be more similar to the photo of a plant than to a person).
The problem is that embeddings tend to be general characterizations. For example, they allow us to configure a detector for animals or plants. But if we want to configure it to detect appliances in our retail store, or electronic products in our e-commerce store, the problem becomes more complex because we need to provide other more specific features.
Another important point is that embeddings are large vectorizations, they have many dimensions, i.e. they are not vectors with a few positions, we are talking about hundreds or thousands of positions. So the problem of finding which image is similar to another (for example, if I need to distinguish a car from a motorcycle or a truck) among billions of images is not trivial, it requires a lot of computation, and this justifies the use of vector databases for massive searches.
What algorithms do these databases usually use to search more efficiently? In general, they search through these Search Nearest Neighbor (KNN) or HNSW algorithms, which is Hierarchical Navigable Small World, based on graphs. In this sense, when we provide a vector, we need the search to give us the most similar vectors to ours. That is, if we want to search for a person in the database, we need to be able to distinguish it from a fictional character or a cartoon.
And here we have the problem of the relationship between the size of the embedding, the specificity of the search, and the time of the (personalized) results. If we have smaller embeddings, the abstraction made is larger, i.e. it is less specific, but the results may be more immediate, though not necessarily efficient. On the other hand, if we have larger embeddings, we can get more specific results, but they will usually take longer.
So the key is to customize and adapt the size of the embedding of my language model according to the application or use case that we need. Let’s say we give OpenAI the entire contents of the Bible, then we tell it that we feel “spiritual emptiness” and “loneliness”, and we ask it to recommend some passages from the Bible to us in the face of this loneliness. This whole process will be very expensive because it will have to process the entire Bible to answer a single question. What would be the solution? Give it the context, the metadata, and the pieces or fragments of text that I really need: if we put the Bible into a vector database, then with my question we look for the passages that talk about loneliness, emptiness and the meaning of life. Then we index the Bible, paragraph by paragraph, book by book, category by category, so if we want advice from Jesus, we don’t look at the Old Testament, we look at the New Testament and the Gospels. That is hybrid filtering, and by asking for that recommendation, we will spend a thousand times less money.
The Importance of RAGs and the Challenges of Vector Databases
Today, these vector databases are involved in augmented retrieval architectures. This is an artificial intelligence framework that combines the advantages of traditional information retrieval systems (such as databases) with the capabilities of large language models (LLM). By combining this additional knowledge with its own linguistic skills, the AI can write more accurate, up-to-date and relevant text for our specific needs, reducing the overall query (so we don’t have to feed LLMs a huge text and can give them domain-specific knowledge). However, it is necessary to delve deeper into each use case to know how to customize the vector database.
What are the challenges of working with vector databases?
- Multimodality: we need our databases to be able to find not only text, but also images, audio and video.
- Business model: it is important to consider which business model best suits our needs, 100% open source, on demand, pay as you go, if the tool is already developed or if it is a known product. For example, there are already well-developed tools like MongoDB or Elastic Search. But there are also native vector databases to which functionality is added.
- Data ingestion: Regardless of how well our RAG techniques are developed, and regardless of the cost and size of the database, the key is Data ingestion. If our documents are of poor quality, not accurate, and do not have the appropriate metadata, our databases will perform poorly. Let’s imagine that we have all the different user manuals for our different products (appliances and electronics) loaded into our database, but we have not provided the database with sufficient information about the characteristics of the product, whether it is a washing machine, refrigerator or television, the database will not provide us with rich information. We need to extract and embed the appropriate text fragments to really answer the questions we need.
- Data pre-processing and context reduction: One of the characteristics of LLMs is that they can «read» PDF documents or documents with a lot of textual content. However, if we reduce the context and tell the machine learning model which chapters or sections of the text we are interested in to answer a particular question, the model will be more accurate and the cost of developing it will be much lower. It is a matter of matching the inputs to the searches so that they are well indexed, preprocessing that data. And the same is true for images, because in embedded images we need those inputs to be well indicated: our model has to know how to distinguish a washing machine from a refrigerator, and it has to understand exactly how each one works. This is where RAGs come in: they provide personalized metadata about the characteristics of each product so that the model can classify them well and work efficiently.
7Puentes: your ally in evaluating the best solutions on the market
At 7Puentes, we have a team of professionals who can advise you on the best solution to manage your AI and ML model data.
We are experts in evaluating and advising you on the correct adoption of technological solutions in databases that are appropriate to the problems and opportunities that your company has, knowing the problems and potential that vector databases offer for the development of these models.
If you are looking for the best advice on database adoption for your company, do not hesitate to contact us.
