
Currently, the need to have a machine learning project architecture and for every AI project becomes a fundamental aspect, which is not only of a high technical level due to the infrastructure it requires, but is also strategic for the company’s business. We invite you to explore and understand the possibilities for managing and integrating a reliable and robust AI infrastructure.
Almost without realizing it, we are increasingly using AI in the technology we deploy in the enterprise. However, there is a lot of confusion within the same organizations, with different names being used for the same concepts related to applications, models and infrastructure, and there is usually no clear reference scheme for managing the technology.
This is because there is still very little progress in the field of enterprise AI: many proofs of concept, but few real use cases in ML, the technique of training a computer to find patterns, make predictions, and learn from experience without explicit programming.
Add to this the hype of those who want to sell us packages of the «best technology» without first understanding what kind of solutions, architectures and workflows we need to plan and implement.
We are referring to both the hardware and software required to develop, test, train and deploy applications based on AI and ML.
The key question as a CTO is: what reference architecture do we need to develop effective workflows that adapt to our models, are sufficiently flexible, but at the same time reliable? How do we order and organize these concepts so that they can be assimilated by the business?
The Kitchen Metaphor for imagining Technology Architectures
A common premise for technology architectures is to describe and organize the elements in layers. That is, the idea that there is a hierarchy, one thing on top of another.
This idea of layers comes from engineering, high level versus low level, because you would talk to a higher level layer and not see the layers below. This idea can easily be broken down into some simple schemes.
This means that the idea of layers is not always applicable and depends a lot on the solution you want to develop. For example, in a kitchen we have different appliances as basic components: gas stove, refrigerator, microwave, electric stove, blender, dishwasher, washing machine, and so on.
What would be the layers in these components? Let’s say there would be none. And in a forced way, we could perhaps think of button panels, sockets, and pipes or tubes in the wall as possible layers. The problem is that, in general, the layers of the project usually interact with each other, and in this case, for example, the gas or electric stove does not interact with the refrigerator, i.e. they do not communicate with each other.
Although each appliance is accessed separately (stove, refrigerator, microwave, etc.), each one solves a problem in itself, just as each software and hardware component solves a very specific problem.
But the truth is that the idea of layers does not necessarily apply to this kitchen. And it is not always necessary to talk about layers, although it is useful to be able to abstract the concepts of a technological project.
Layers of a Machine Learning project architecture and AI infrastructure
Because the structures and infrastructures are usually so complex, we take the precaution of talking about layers in this reference architecture for AI projects. Understanding that it is a scheme that we should think of as flexible and malleable to our needs.
In this sense, it is sometimes useful to organize projects in layers to simplify the interaction between components: a layer interacts with lower or higher layers, but nothing more.
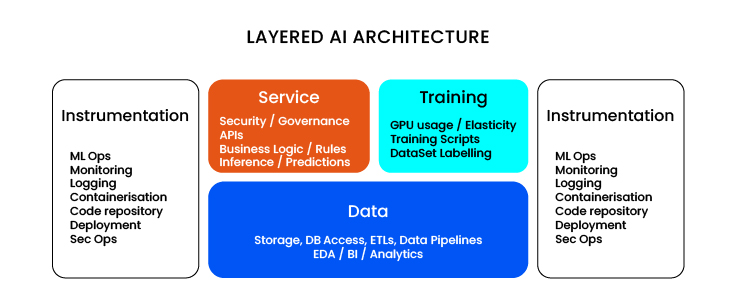
The main layers that exist in this type of AI and ML projects would be:
- Data layer: This would be the lowest layer, but we have to clarify that you usually access the data directly. But not only the data in the form of files, images, folders, databases, but also in all the processes that make up the transformation, ingestion and operational work with the data. So we call this process «pipeline», or we can call it ETLs (all the work of extracting and transforming the data). And there we need to introduce the next level of data processing, which would be an “analytics” sublayer. This means that by having a database, you can now perform an analytics task, for example, a SQL query directly on the editor and extract insights that can be dumped into a form or report.
- Training layer: This AI model training layer is separate and has its own complexity. Unlike the other layers in our project, we must understand that it is an on-demand layer, which means it is temporary in our structure: once the model has been trained and the results of that training have been used efficiently, the machines are turned off. Nowadays, the size of the infrastructure is very important. For example, GPUs are used to train LLMs, which can even run on virtual machines to simplify the computation, or even supercomputers with HPC, and they spend hours and hours training the machine learning model, doing inference on the data, and calibrating it.
For all of this, we label our dataset and run scripts with training code, which is typically generated by the team of data scientists and requires sufficient elasticity to be trained on our infrastructure.
- Service layer: Unlike the previous one, the service layer is permanent and has other related issues: computer services and software applications must be reliable and always operational, with 24/7 support. Services can never go down. Another key point is the security, regulation and governance policies of these services: defining whether to have APIs or not, defining who accesses them and with what permissions, thinking about how to adapt the applications to the business logic, and integrating the different components into my project so that they are sufficiently robust and efficient in their operation are some of the most important challenges in the service layer.Unlike the training layer, which we could call «laboratory» because some testing and experimentation issues can be relaxed, this service layer must have very clear and strict rules both in access and in the use and implementation of the systems.
- Instrumentation layer (transverse to all other layers): The last layer is the instrumentation layer, generally the «orchestration» of all the elements, which touches and crosses all the other layers. It is important to understand that instrumentation would not necessarily be a hierarchical layer, because in all these layers there are processes with programs that need to be monitored and cohesive. When we implement our ML model, it’s important to have monitoring if the training went well or badly and if any process needs to be repeated, while in the service layer we have an API and we want to see its consumption, who is accessing it, what questions are being asked, etc. and this is the responsibility of the project to include all the activities of DevOps, SecOps, MLOps, deployment, the GitHub code (who manages it) and if we have containerization (Docker) with access and security credentials for those repositories.
The infrastructure is so complicated that it requires this constant control, as if it were an audit, the management of this technology carries that responsibility. Many people don’t realize this because they often underestimate the complexity and scope of the project architecture.
For example, you might wonder: Why we really need an image repository in Docker? But when you’re building a service component, if it takes 20 minutes, it’s not the same as if it takes 20 seconds. Docker is very convenient, but it requires that the images of the components it contains be updated with the Internet. To speed up this process, a local repository is introduced that is very close to the same cloud from which you are going to deploy the components. Otherwise, every time you want to build the images, you spend 20 or 30 minutes building things, and that’s too much time.
The kitchen in our home as a control panel
The key to this process is to think about how we used to run an “.exe” program or a code editor on a single server or application, and now we have dozens or hundreds of connected machines that also need more processing power, scalability and support.
Let’s imagine that a CTO has several projects and each of them is built with a container and also has an elastic infrastructure where services are created and destroyed on demand: this is a very technical but very clear example of something that used to work in a much simpler way. We need to understand the dynamics of how these components work, individually and together.
Going back to the kitchen metaphor, if we only have one appliance, we don’t care about the manual, we don’t care about the warranty; if it breaks, we call a technician to fix it. Even if it’s under warranty, we don’t care because it’s just an appliance.
Now, if you have an air conditioner, an exhaust fan, a microwave, a washer, a dryer, a dishwasher, a stove, an electric oven, a boiler for heating, that’s almost ten appliances. At least we’ll have all the manuals together in one folder, and if we need technical service, we’ll have a trusted phone number for someone who can solve the problems of this structure, and maybe we’ll buy everything from the same brand, or go to the same retail outlet, because we organize ourselves and do things differently.
And that’s the responsibility of orchestrating a complex ML project architecture, because if the CTO has the logs (service log files), there are now at least 25 services. And it’s logical that everything is centralized.
For all the reasons we mentioned, we need to have control of the infrastructure and the costs, we need to know if the machines are on or off, and we need to understand that in the code of our software we have data pipelines, training scripts, all the source code of the APIs of the services, and so on. All of that leads to a Power BI dashboard, and the dashboard code, all of that code is in Git, and that Git is in a repository that has to be kept up to date all the time. And the quality of the code has to be maintained, it has to be controlled. Now we have between 40 and 50 projects, each with its own repository, whereas before we had very few, and we did not think about centralizing or connecting the projects.
7Puentes: a valuable partner for your own AI infrastructure
If you are in charge of technological information in your company and you have doubts about how to manage this complex, flexible and scalable architecture for your AI and ML projects, this is your opportunity to consult our specialists.
We can help you define strategic policies to better organize, order and plan your technological architecture so that your projects are more efficient, you save costs and improve the profitability of your AI with us. Do not hesitate to make 7Puentes your strategic ally.
