
The tremendous progress in generative artificial intelligence presents companies with the dilemma of which techniques to choose to develop or refine their large language models. Among these main alternatives are fine tuning and zero shot learning. In this post, you will discover the variables and conditions that can guide the choice of one path or the other, depending on the company’s business case.
In the era of digital transformation, Large Language Models (LLM) have revolutionized the field of artificial intelligence, providing advanced text understanding and generation capabilities that are transforming business operations. These models have found applications in a wide range of industries and organizations. However, their implementation is not straightforward, and managing large volumes of data poses significant challenges in terms of resource consumption, cost, latency, security, scalability, and performance.
The need to make decisions about the best techniques for developing and continuously adapting LLM models is a critical aspect of Gen AI.
What are the differences between Fine-Tuning, Zero-Shot Learning and Few-Shot Learning in this complex context?
- Fine tuning: The Oxford dictionary defines fine-tuning as «making small adjustments to something to achieve better or desired performance». Today, fine-tuning in Generative AI is becoming a key phase to achieve the maximum level of customization and thus the value of this technology.
It is a technique by which we take a finished model, retrain it with a variety of concrete examples, and store the updated weights as a new control point of the model. Fine-tuning, which is in vogue today, comes from something called transfer learning. In this case, in our neural network, the weights of the neural network, all the parameters that the network has inside, are initialized with random values. Then we provide examples and we train a neural network.
But it is trained from scratch. Transfer learning involves training a neural network, or continuing the training of a neural network, but not from scratch because we have already started with weights. These cases often occur in computer vision problems, for example, when networks are trained to recognize dogs and cats, or to recognize a famous person. Fine tuning is the same concept, but has the idea of specialization, of making it specific for a task by fine tuning.
- Zero shot learning: This is a technique where we start an LLM without any examples and try to take advantage of the reasoning patterns it has acquired (i.e., a generalist LLM that is used as is and is about finding the right prompt to do the task we want).
Doing zero-shot learning is part of the democratization of access to Gen AI (since anyone can look for a prompt, set a task for it, and see if it works or not), for this reason it is usually technically simpler. In this sense, the model can work without labeled examples and classify only based on what it has learned from the general data.
Zero shot learning allows a model to perform a task without having received specific training for it. For example, a model can summarize a paragraph, answer trivia questions, or translate text based only on its general understanding of the language from reading a large amount of text during its training. It does not need any examples to perform these tasks.
- Few Shot Learning: This is a technique where we start an LLM with some concrete examples of task performance. It is a very good complement when zero shot learning does not work.
In this case, a model is given some examples to learn a new task. Unlike zero shot learning, it uses these examples to better understand what it is being asked to do. For example, you can give a model some examples of questions and answers, and it can use this information to answer new similar questions more accurately.
It often works better than zero shot learning because it has some context to work with and does not yet require a large amount of data. However, it depends on the quality of the examples provided. If the examples are poor, the performance of the model will suffer.
Pros and Cons depending on the use case
It is important for a business decision maker or the operational manager of the project to consider the advantages and disadvantages of each technique for an LLM model.
In principle, there is no natural order to follow one way or another, it depends fundamentally on the human and material resources available to the organization and the use case that needs to be solved.
While it is true that fine-tuning improves the specific performance of the task, adapts better to the use case, and reduces risks, it is usually expensive due to the resources it requires, and the model requires a lot of data and a lot of time to train. Not every company can afford to do this, since it is important to have a specialized team of programmers.
There are situations where the problems are so overwhelming that it is still difficult (or almost impossible) to implement fine-tuning.
For example, if we want to develop a disease diagnosis model that takes into account all the clinical histories of the entire history of Argentina, it may not be possible. It is very expensive, and the data is so dirty that healing the data is an endless process that we never finish.
So the important message is that it is one thing to do fine-tuning with a small model (e.g., medical records of a health institution) to specialize and improve it, but there are situations of fine-tuning that are not possible no matter how much we want to do it.
An important variable is that the size of the prompt and the context are paid. So in few shot learning, when the number of examples is very large, LLMs are often used to classify. For example, this is the case of the HSE conversational agent for safety (see previous post), where we have a text and we need to determine which accident category it belongs to. We have 100 categories, with an average of 10 examples per category, which gives us 1,000 examples. If we build a system to classify an observation and we pass the 1,000 examples to each classification to tell us which risk category it belongs to, it is an expensive process.
So the more deterministic the task (we have this input and this is the output), the more effective and productive AI is for generative tasks. If we ask it to categorize a security observation and there are tons of examples, or diagnose this pathology with these symptoms, it is possible to do it with a few examples, but if there are 5,000 records, we cannot do a few shot learning with that.
Let’s say you want the model to classify our text as «spam» or «not spam». The model is given a few example sentences that are labeled as spam or not spam, such as «Congratulations! You have won a free prize. Click here to claim your prize», which is marked as spam, and «Agenda for tomorrow’s team meeting«, which is marked as not spam. From these few examples, the model learns the characteristics and patterns that distinguish spam messages from normal messages. So when it finds a new message, it uses these examples to make a more accurate classification. This is a feasible task.
The reality is that if we have a lot of our own data and the task is deterministic, it works. If the vocabulary is strictly domain-specific, you have to customize it with a pass through your own data to get that vocabulary into the model. Especially because there are concepts such as the vocabulary or dialect specific to a country or a very technical vocabulary, such as «stop» in the industry, which has its semantics with different meanings.
Key Parameters of Traditional Machine Learning
At the same time, in this process of making the best decision for the project, the need for specialized knowledge of traditional machine learning appears. In this sense, there are three very important parameters:
- Epochs: the number of times we pass the same data to the model, it is like the number of times we read the textbook for an exam. This influences the result.
- Learning rate: how fast we read the information and data, how fast we adjust the weights of the model, or adjust our learning to what we read.
- Batch size: it also affects the speed at which we read, but it has to do with how much information we process together at the same time. In this case, the weights of the neural network are updated per batch.
On the other hand, in this graph below, we can understand the balance between what the model needs with the correct input to the model (top line) and the model itself being optimized (right line). In this case, all possibilities are considered.
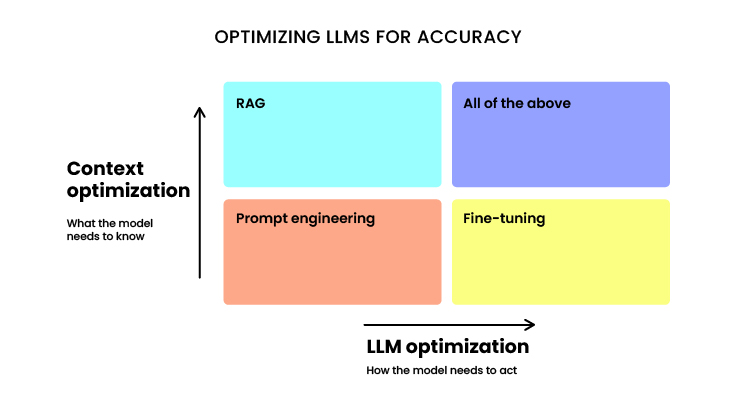
Of course, once we have a fine-tuned model, we can also do zero-shot learning, for example, in an energy safety and hygiene model where domain vocabulary is added and updated, and then do few-shot learning with more examples, and maybe it works better as it is updated.
So while there is no natural order, there are situations that favor one way or the other, they are not mutually exclusive. We can improve the input, improve the prompt, improve the number of examples with a RAG system, add domain vocabulary while fine-tuning the model, and finally we can take a GPT or LLAMA (not the very big ones), introduce that domain information (let’s imagine we have all the emails, technical documents and reports for an oil company), if what we are looking for is for the model to learn from the domain and progressively improve.
7Puentes as a strategic ally
We are a company with more than 16 years of experience focused exclusively on the development of solutions based on AI and Machine Learning.
Our services are tailored to the needs of each company. We believe that AI can transform any organization, regardless of its maturity, creating real value and optimizing existing processes.
We have extensive experience in developing machine learning models and are currently working on supporting large language model solutions in a variety of projects for different industries.
If you need to determine which techniques, tools and solutions are best suited for your Gen AI project, contact us for a personalized consultation. Remember, effective budget planning is crucial for successful AI project implementation. For insights into AI development budgeting, you can refer to this resource.
