
Text-based safety observation classifier
In this use case, you will learn in detail how we were able to develop a text-based safety observation classifier for our oil and gas customer, and how this innovation will provide the customer with insights to improve the work experience, reduce accidents, and maximize profits.
The oil and gas industry is undergoing a profound transformation driven by the digital revolution. And one of its fundamental drivers is based on artificial intelligence, with solutions focused on automation, intelligent real-time data management and risk reduction, as well as the best in safety based on predictive maintenance.
According to a recent industry survey (Ernst & Young), 92% of oil and gas companies worldwide are investing or planning to invest in AI over the next five years. And 50% of oil and gas executives say they are using AI to solve challenges across their organization.
Although in a previous post we explained how to develop a conversational agent solution for EHS, in this new post we show a real use case for automatic classification of safety text in the oil and gas industry.
In this context, the company that hired us receives daily safety observations (records with written text) from employees working in different areas. These observations refer to daily irregularities by other employees (e.g. missing safety elements, broken signs, non-compliance with regulations, etc.).
The problems at the beginning of the project were
-Given the large number of observations received (hundreds of thousands per month), the team of experts in the field is not able to classify them all, and expanding the team is not scalable or practically impossible.
-In practice, different experts in the field may have different criteria for the possible consequences of these observations.
The Value of the MLOps Methodology
Today, machine learning operations are combined into a valuable practice called MLOps that automates and simplifies machine learning (ML) workflows and implementations. Any organization or business can use MLOps to automate and standardize processes throughout the ML lifecycle. These processes include model development, testing, integration, deployment, and infrastructure management.
When we talk about MLOps, it is not only about code management, deployments and model infrastructure, but also about standardizing the way these models are worked with and managed. For this reason, it is not only about tools, but also about very clear working policies.
At 7Puentes, we use the MLOps methodology for this automatic text classification project, which allows us to develop solutions that facilitate or accelerate the work with our clients. In this way, 7Puentes has worked intensively and quickly with the Machine Learning and Data Science departments of the company, which required the technical solution according to the specific needs of these teams.
The use of MLOps has significantly reduced time and improved data ingestion, model training, and project delivery. And the benefits are direct to the security domain. Of course, the use case can be adapted according to the objective of each project, as the methodology is flexible enough. This framework is already extremely valuable for both our technical development and our teamwork.
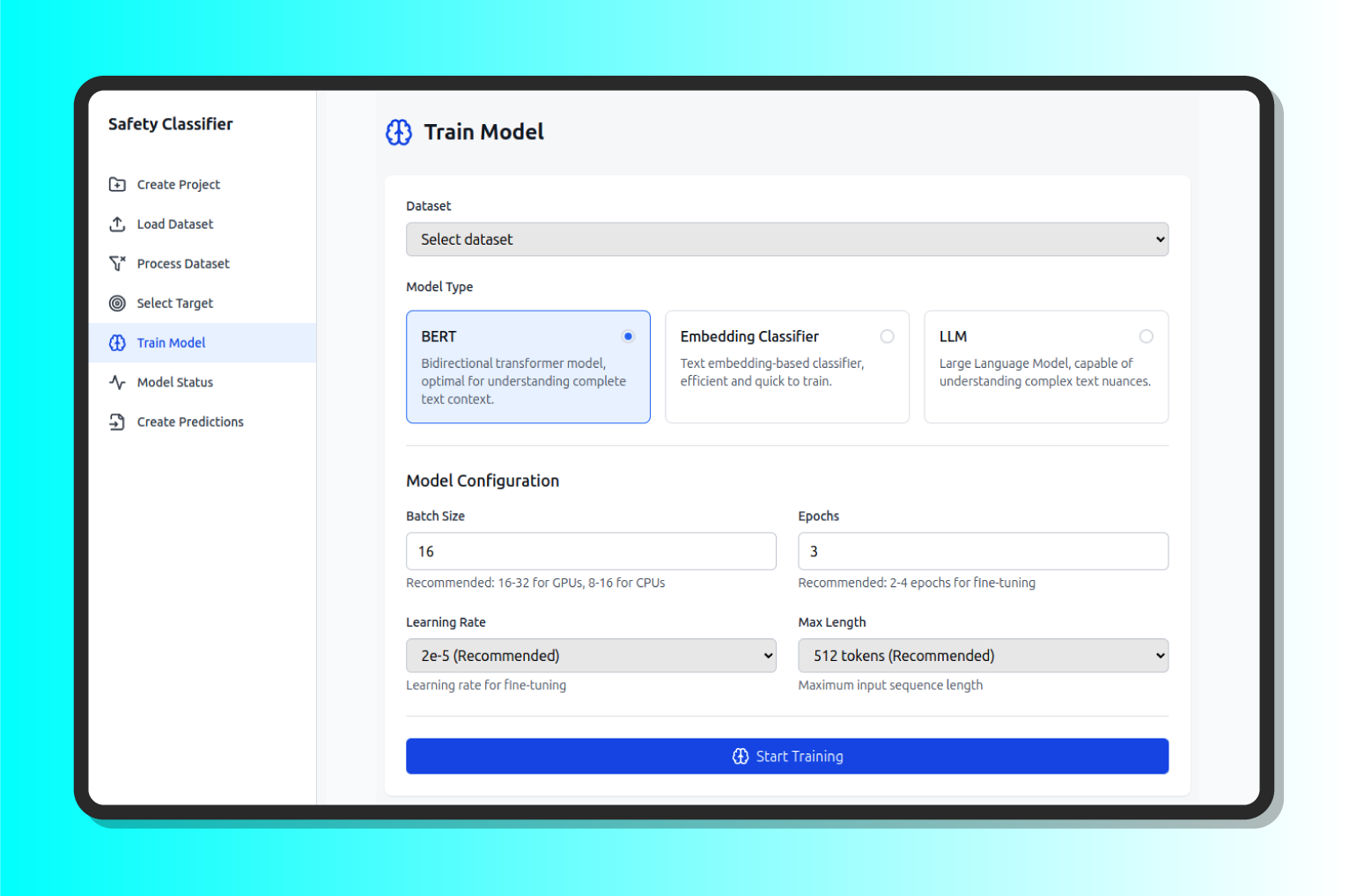
Another advantage of our development is that it can be used for any type of security observation, since we have performed A/B testing depending on the problem to be solved and we have been able to combine different language model techniques. In this way, models can be developed that are oriented towards BERT (an optimal bidirectional transformer model for understanding the full context of the text), Embedding Classifier (a classifier based on text embeddings, efficient and fast to train) and LLM (Large Language Model, capable of understanding complex nuances in the text).
The Platform Design Process
Here we describe the functionalities developed to guide a domain expert to easily classify the data he has in tabular formats such as csv. The complete process consists of
- Menu: The menu presents the options in a sequential manner, since each step of this process requires the previous task to continue:
- Create Project
- Load Data Set
- Process Data Set
- Select Target
- Train Model
- Model Status
- Generate Predictions.
- Projects: Projects group the data related to a particular case so that the user can keep track of and organize his or her work. In addition, it provides information and context that can be used by the language models to better understand the problem to be solved (the project contains the files and models for classifying safety observations).
- Data Sets: This section manages the files and data that will be used to train or test the classification models. You can create and save datasets with different data to test the different models and evaluate their results. This module allows loading local files, synchronizing with the main storage clouds and connecting to existing databases.
- Preprocessing: Once the data sets have been loaded, they need to be processed. In order to obtain the expected results and to ensure that the training of the models does not fail, it is necessary to ensure that the input data are suitable to be consumed by the models. To do this, it is necessary to correctly categorize the input variables, cleanse or impute missing values, and select the variables to be used as input to the model.
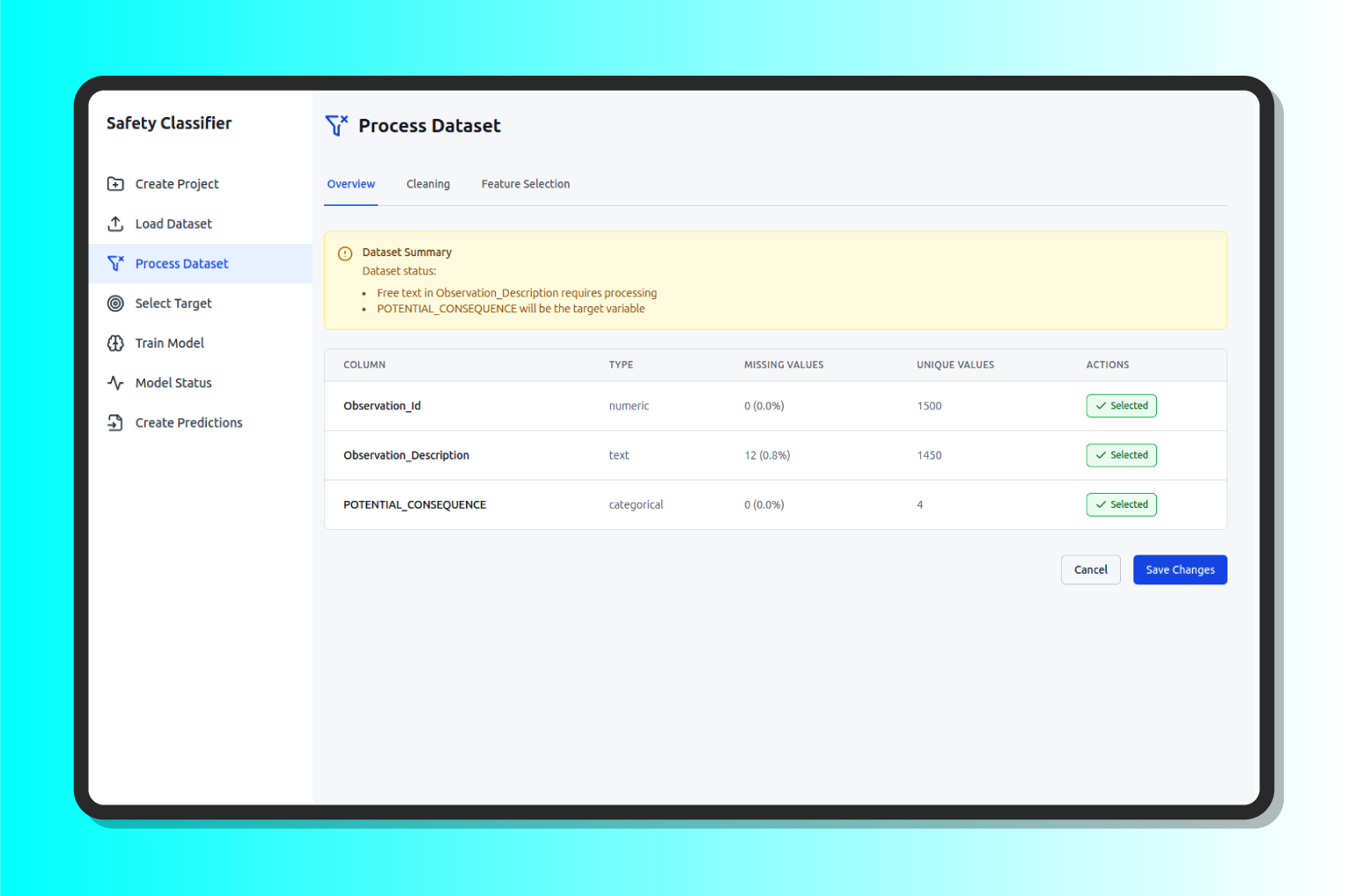
- Target: The «target» or objective variable is the value that the model must reach after its training (the output), it can be one or more depending on the case.
- Training: With just a few parameters, we can train a classification model. The first step is to select one of the datasets loaded and configured for this task, then choose from a variety of more powerful models adapted to our platform, entirely designed by 7Puentes to be the ideal solution. This task can take from a few minutes to a few days, depending on the data and the model chosen.
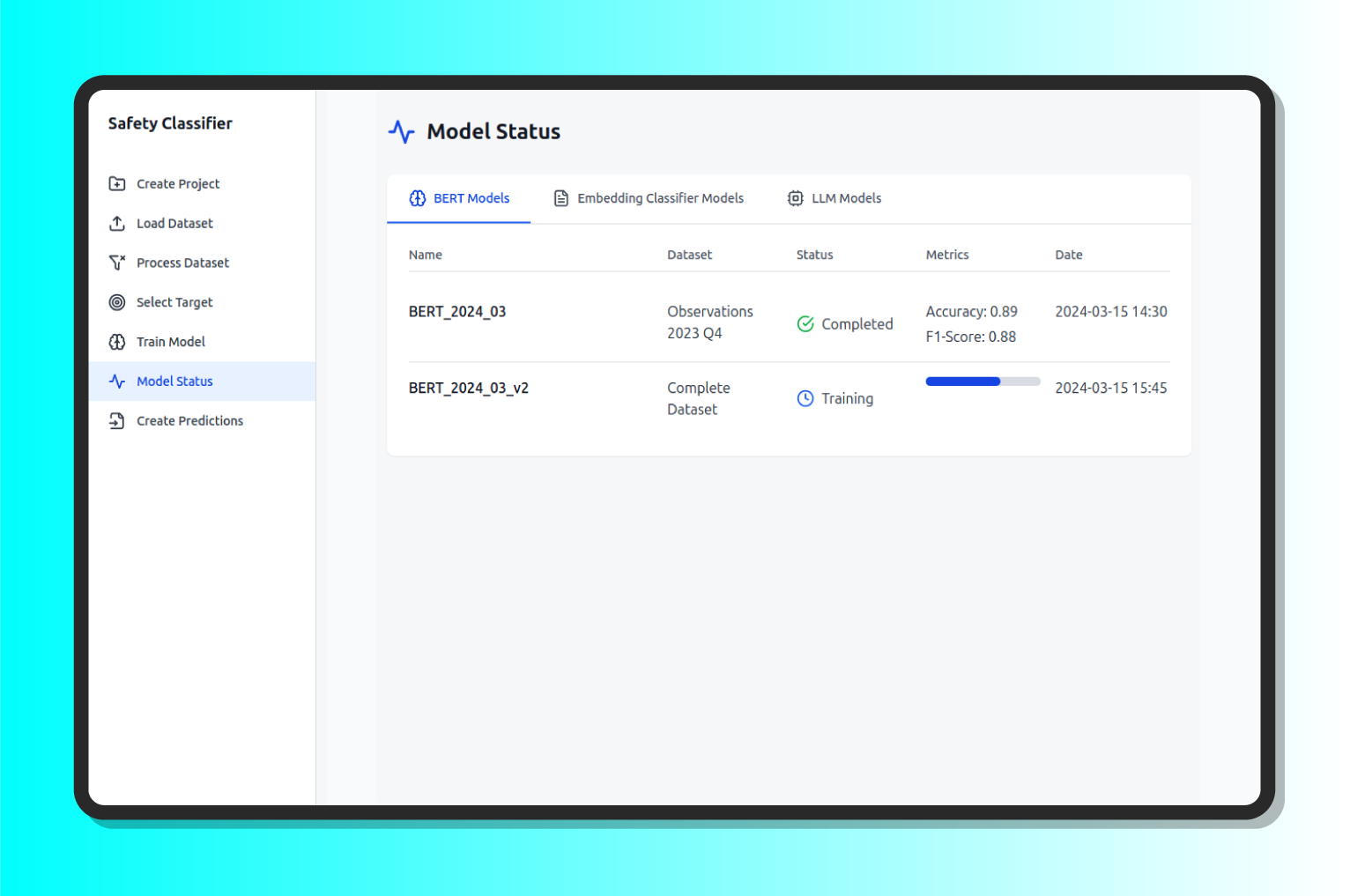
- Status: This option shows us the progress of each model that has started its training, as well as the metrics related to the accuracy of its predictions.

- Predictions: The last step is to generate the prediction of new observations. To do this, the user must load a data set containing the features selected above.
Final Benefits of the Project
This project aims to benefit two very specific areas of our customer: the security area and the data science area.
On the one hand, the Safety area will benefit from the knowledge gained by classifying the data. In this way, it can reduce accidents, irregularities and failures, or problems related to worker safety.
On the other hand, Data Science benefits from the centralization of trained models in a single repository, where it can compare previous model versions with new versions, update the model to be used in a production environment with a few clicks, and retrain models with new data or monitor those in use. It also eliminates the need to have specific data science skills to train a security observation classification model, making this task 100% democratized.
Undoubtedly, this use case shows the prospects of success for any oil and gas company that can take advantage of these very practical and beneficial solutions, adding more and more value to the business model and reducing risks in daily operations.
